News
/
无需特异性样品制备,实时靶向富集测序:利用灵活性采样进行的选择性纳米孔测序
04 February 2020
最新发表的两篇论文使用实时纳米孔测序和名为“Read Until” 应用程序编程接口(API),展示了无需预先进行样品制备的靶向测序的动态工作流程。论文描述了一种基于电子原理、能够从混合样品中实时选择感兴趣的分子的方法。
在今天发表的预印版文章中,Kovaka等人和Payne等人利用“Read-Until” API进行纳米孔测序,展示了在无需进行靶向特异性样品制备的情况下,使用纳米孔技术对感兴趣区域进行快速测序的未来潜力。

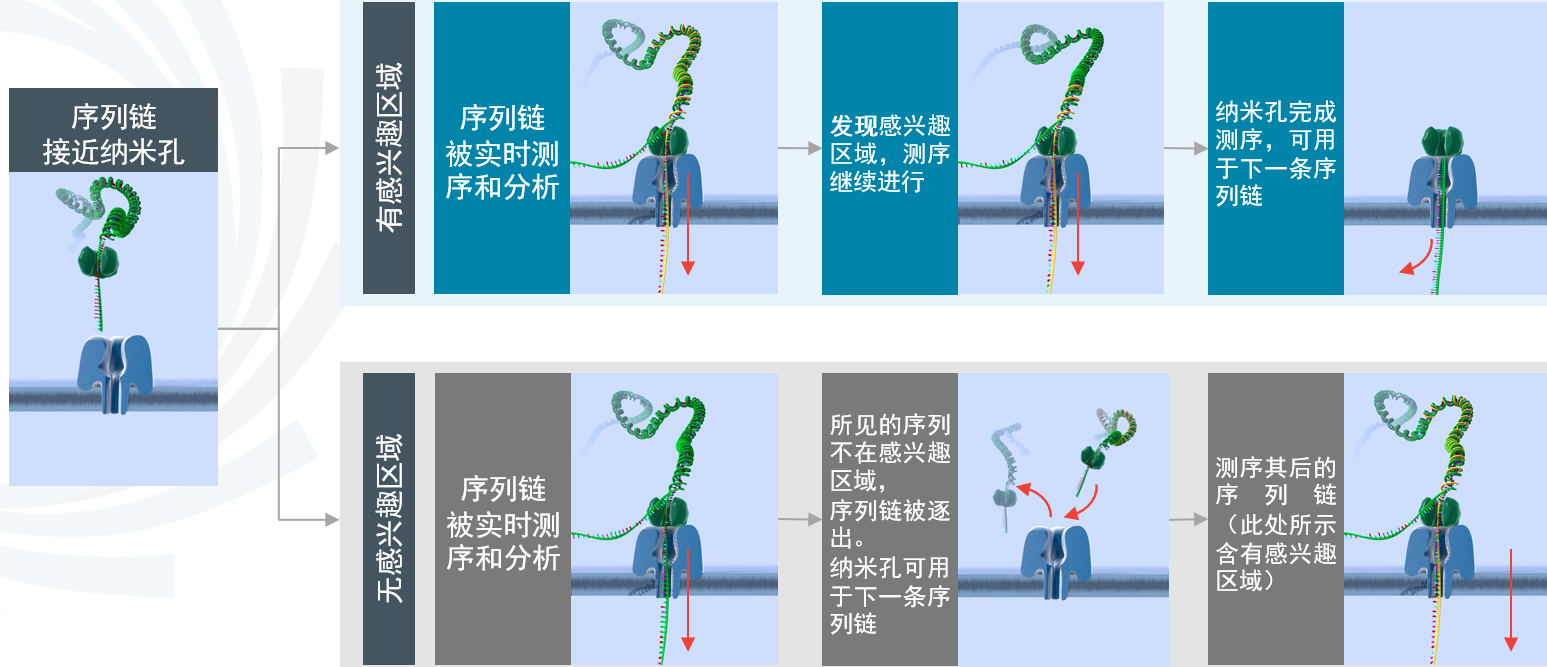
灵活性采样(Adaptive sampling)
图1:灵活性采样(adaptive sampling)的机制是使用户根据软件中指定的配置对系统进行编程,进而能够选择接受或拒绝序列链。
Kovaka 等人 开发了一种新颖的原始信号定位算法,该算法能够通过灵活性采样(adaptive sampling)来富集与遗传性癌症相关的148个人类基因的测序,并在单个MinION测序芯片上实现30X覆盖度。与50X覆盖度的短读长全基因组测序相比,该方法检测到了超过两倍多的结构变异(SV)数量,并且能够准确识别小型变体及分析DNA甲基化。 阅读预印版论文.
Sam Kovaka博士指出:“这种通过简单的低成本测序运行,即可全面检测任何基因组区域的遗传和表观遗传学变化的能力,将彻底改观对癌症的治疗和预防,传染病特征分析以及许多其他应用。”
与此同时,Payne等人.也展示了对多个样本进行的规模可扩展的灵活性采样(adaptive sampling),并指出使用图形处理单元(GPU)进行直接碱基识别,速度足以进行选择性测序,并且可以扩展规模。该方法早在2016年就被同一团队发表于《自然》杂志。 作者在最新的发表论文中描述了:
Alex Payne博士指出:“Read Until可以对大型基因组的众多区域、或多个基因组的特定子集进行快速、灵活的适应性测序。通过减少测序和样品制备两者的时间和成本,这些方法将使研究人员能够将长读长测序集中在特定区域上,从而解决生物学问题。”
靶向测序,或从样品中选择目标区域,通常涉及在测序前对DNA进行大量操作。这可能涉及PCR步骤,Cas介导的富集或杂交捕获,每个步骤都可能使制备和手动时间增加数小时或数天,并且增加成本。通过在测序过程中实时地选择分子,即可以去除这些步骤,从而达到简化过程的目的,同时也保持了样品中所存在的DNA修饰,加速对生物学问题的解答。
灵活性采样(adaptive sampling)的应用方向及潜在应用
灵活性采样(adaptive sampling)使得大量的应用可以通过非常基本的样品制备便得以进行,而复杂的目标选择则由测序仪本身来完成。
正如这两篇论文所证明,Read-Until 可用于富集包含目标区域的序列链,在保持所有长读长测序的优势的同时,显着的降低成本。用户也可以使用它来“拒绝”与兴趣无关的生物序列链。例如,在微生物组的应用中,这可以提供更简单的工作流程,规避在样品制备过程中去除宿主的需求。
灵活性采样(adaptive sampling)的另一个用途是可以均衡覆盖度,不论是条码标签(barcode)或是扩增子测序,以确保获得对感兴趣区域的均一的目标深度。
利用Read Until API
Read Until API将在有限的支持下,作为研究工具在Nanopore社区提供,我们的团队现在正在研究一个新的简化版的灵活性采样(adaptive sampling) API,预计将于今年晚些时候上线。有关更多信息,请访问Nanopore社区发布(login required)
如果您希望通过Oxford Nanopore了解有关灵活性采样(Adaptive Sampling)API 的最新信息,请在这里注册意向.
论文